
The Webinar Recording:
Firstly, I want to thank Exterro and ACEDS for the opportunity to speak on this webinar. I found it a valuable experience and should the right topic come up I would like to take part in another one.
My favourite slide from this presentation is the “A Day in Data”, which shows the vast volume of electronic data that we create everyday:

Stuart explains during the webinar that we are now producing the same amount of data every two days that we did from the beginning of time up to 2003. That is just mind blowing. The info graphic above also shows us that in 2013 the accumulated digital universe of data was 4.4ZB (zettabytes), by the end of this year (2020) it is expected to have grown to 44ZB. In seven years the total volume of data has grown by ten times.
Final Thoughts:
I want to revisit the first question that Stuart Davidson, Marketing Director at Exterro asked me: “What is the biggest challenge that we face in eDiscovery”. My answer was and will always be our clients. This isn’t to be taken as a slight on our clients, but when dealing with data if you don’t understand the process that is required to take a custodians data set (laptop, mobile, tablet, email, etc.) and convert its content to be be reviewed online then it is understandable that as professionals in the industry we often end up with really tight deadlines. Our role here is to educate our clients, they do not need to comprehend the technicalities of processing data just that there are elements of time that can not be changed, such as copying data from the source to your servers for processing (we make a back up copy too) and then the time it takes to process the data and run whatever culling techniques before pushing the data into a review platform. When having a project kick off call with a client who isn’t well versed in eDiscovery, we should take the time to explain the steps that need to take place to get the data from A to B to C. Sometimes though it is already too late the deadline is looming and the eDiscovery is a last minute task.
As I mention above Time is a big factor too, this is something that plays a big part in the challenges we face, not only will time be reflected in the deadline but also because the more data there is, the longer it will take to do different tasks, from the simple stuff like copying data from the source to the internal network but also the time it will take to process and ultimately load into Review. If the systems in use are all cloud based then the copying data may take even longer as you cannot take a drive to the servers and copy it locally you have to upload data into a virtual network on someone else’s servers, so that you can then action it and the time will be determined by your internet upload speed.
A challenge that wasn’t listed on this slide is Information Governance. If you do not know where the data resides then it can cause huge issues, from identifying the which data sources, to getting the data for collection and processing. This will be particularly important should an organisation get a DSAR.
I think that we covered the data reduction techniques well during the webinar so I am not going to add anything, except, it is important that we make use of the technology we have to assist our clients with the best course of action to proceed in a case. Give the client all the information so that they can make an informed decision, it is no longer acceptable that the only options to review voluminous data is a linear review, technology should be used appropriately.
Finally, Damian Murphy was asked “In which stage of the EDRM is Artificial Intelligence (AI) most important?” Damian’s answer was Information governance.
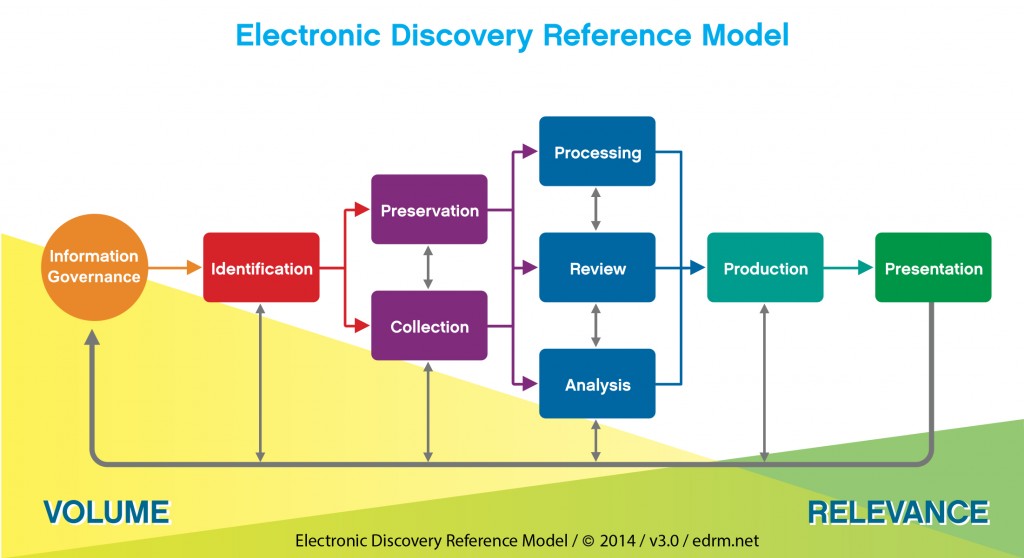
If I had been asked that same question would I have answered in the same way? I don’t think so, I do not necessarily disagree with what Damian said but I think that Identification might be a more valuable stage for it to be used on. The reason I think this is because Information Governance is about sorting through your data and knowing where it is and whether you have it in the correct place. Identification is about finding the data for your case, be it electronic or paper, on a mobile or a laptop. If we could deploy an AI feature that would locate this data and whose data this could save time and money. Having a good information governance structure would obviously allow for this to happen so this is why I do not disagree with how Damian answered the question.